Gesture Only
This baseline only uses gesture to interact with the robot. Here we implement several buttons to represent actions.
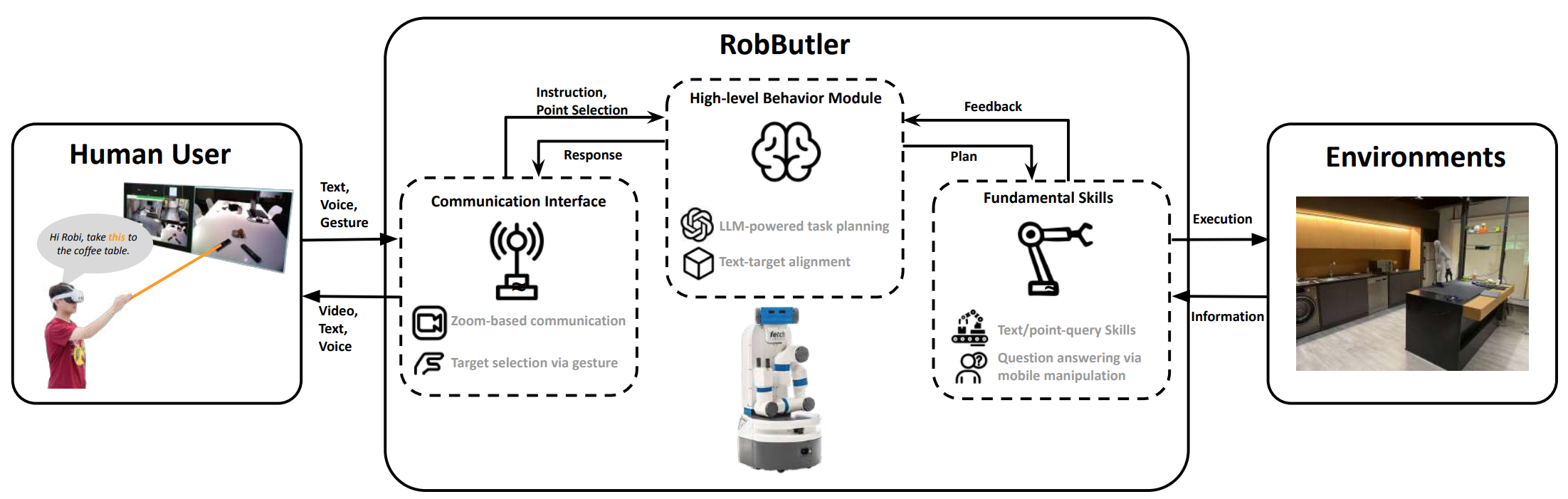
Imagine a future when we can Zoom-call a robot to manage household chores remotely. This work takes one step in this direction. Robi Butler is a new household robot assistant that enables seamless multimodal remote interaction. It allows the human user to monitor its environment from a first-person view, issue voice or text commands, and specify target objects through hand-pointing gestures. At its core, a high-level behavior module, powered by Large Language Models (LLMs), interprets multimodal instructions to generate multistep action plans. Each plan consists of open-vocabulary primitives supported by vision-language models, enabling the robot to process both textual and gestural inputs. Zoom provides a convenient interface to implement remote interactions between the human and the robot. The integration of these components allows Robi Butler to ground remote multimodal instructions in real-world home environments in a zero-shot manner. We evaluated the system on various household tasks, demonstrating its ability to execute complex user commands with multimodal inputs. We also conducted a user study to examine how multimodal interaction influences user experiences in remote human-robot interaction. These results suggest that with the advances in robot foundation models, we are moving closer to the reality of remote household robot assistants.
The robot system consists of three components: Communication Interfaces, High-level Behavior Manager, and Fundamental Skills. The Communication Interfaces transmit the inputs received from the remote user to the High-level Behavior Module, which composes the Fundamental Skill to interact with the environment to fulfill the instructions or answer questions.
This baseline only uses gesture to interact with the robot. Here we implement several buttons to represent actions.
This baseline only uses voice to interact with the robot. We adopt TIO as the visual grounding module.